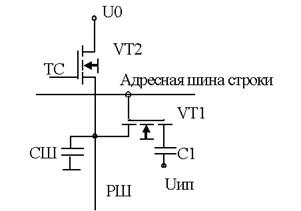
Рис.1. Элемент динамической памяти на МОП структурах
Динамическая память. Элемент памяти, микросхема памяти
Динамическая память - DRAM (Dynamic RAM) - получила свое название от принципа действия элемента памяти хранящего один бит информации. Запоминающим элементом служит конденсатор, являющийся емкостью перехода исток - сток полевого транзистора. При записи логической единицы в элемент памяти конденсатор заряжается, при записи нуля - разряжается. При чтении информации конденсатор тоже разряжается и, если заряд был не нулевым, усилитель считывания устанавливает на своем выходе единичное значение потенциала, и конденсатор специальной схемой перезаписи снова заряжается до потенциала логической единицы. При отсутствии обращения к элементу динамической памяти со временем, за счет токов утечки, конденсатор разряжается и информация теряется, поэтому такая память требует периодического перезаряда конденсаторов методом перезаписи каждого элемента (регенерации). Следовательно, память может работать только в динамическом режиме, с постоянно повторяющимся процессом перезаряда конденсаторов ячеек памяти.
Этим она принципиально отличается от статической памяти, реализуемой на триггерных ячейках и хранящей информацию без обращений к ней – статично, сколь угодно долго при включенном питании.
Благодаря относительной простоте ячейки динамической памяти, на одном кристалле удается размещать много миллионов ячеек и получать сравнительно недорогую полупроводниковую память, пускай и недостаточно высокого быстродействия, но с умеренными энергопотреблением и ценой.
Используется динамическая память в качестве оперативной памяти компьютера, оперативной памяти видеокарт и других устройств.
Работа запоминающего элемента динамической памяти. Микросхема динамической памяти состоит из миллиардов элементов, каждый из которых хранит всего один бит информации. На физическом уровне элементы памяти объединяются в прямоугольную матрицу, горизонтальные линейки элементов называются строками (Row), а вертикальные - столбцами (Column).
Элементы всей строки матрицы могут считываться в современных микросхемах динамической памяти в буферный регистр - этот набор ячеек принято называть страницей (Page), не путайте со страницей виртуальной (кажущейся реальной) оперативной памяти.
Из-за высокой интеграции элементов памяти в
микросхемах динамической памяти становится невозможным обратиться к ячейке,
установив на шине адреса адрес ячейки памяти полностью. Слишком много разрядов
должна иметь эта шина. Поэтому шину адреса делают в два раза уже и
устанавливают адрес дважды. Сначала адрес строки, затем адрес столбца. Чтобы
различать, установка какой части адреса происходит,
вводятся дополнительные сигналы управления RAS и CAS. Адрес строки передается
по шине адреса и принимается в регистр адреса строки микросхемы памяти по спаду
импульса RAS (Row Access Strobe). Адрес колонки передается по этой
же шине и принимается в регистр адреса колонки микросхемы памяти по спаду
импульса CAS (Column Access Strobe). Таким образом, адресная шина работает в
режиме мультиплексирования,
т.е. адреса строк и столбцов передаются по одним и тем же проводникам, поэтому
и адреса, и сигналы RAS# и CAS# передаются не параллельно, а
последовательно, один за другим, с разделением во времени.
На пересечении линии строки и колонки находится
элемент памяти.
Поскольку обращение (запись или чтение) к различным
ячейкам памяти обычно происходит в случайном порядке, то для поддержания
сохранности данных производится регулярная регенерация (Memory Refresh – "
освежение" памяти) – регулярный циклический перебор ячеек памяти с
холостыми циклами перезаписи. Регенерация в микросхеме происходит одновременно
по всей строке матрицы элементов памяти при обращении к любой из ее ячеек.
Если динамическая память используется в
видеобуферах графических адаптеров, то специальных циклов регенерации такая
память не требует, так как частота ее чтения для воспроизведения изображения на
экране видеомонитора вполне дотаточна для сохранения информации при
чтении и сопровождающей чтение перезаписи.
Микросхемы динамической памяти строятся на основе
полевых транзисторов. Элемент динамической памяти на полевом транзисторе
показан на рис.1.
В основе запоминающего элемента лежит один конденсатор
С1 и один МОП транзистор VT1. На схеме конденсатор
показан в виде отдельного элемента, хотя реально его функции выполняет емкость
затвор-подложка. Транзистор VT2 открывается сигналом ТС=1 и от источника U0
емкость СШ заряжается до напряжения U0.
При выборке данных транзистор VT1 выполняет функции
ключа: при подаче сигнала на шину адреса строки он открывается и соединяет
запоминающий конденсатор С1 с шиной столбца РШ
(разрядной шиной).
Рис.1. Элемент динамической памяти на МОП структурах
Емкости конденсатора шины (СШ),
поэтому возникает незначительное изменение потенциала шины, которое усиливается
при считывании информации высокочувствительными дифференциальными усилителями.
На вход дифференциального усилителя подается напряжение
разрядной шины и опорное напряжение для определения разности. Опорный элемент
поддерживает опорное напряжение U0.
Память организована в виде матрицы. В каждом столбце матрицы памяти (РШ) расположены шинные усилители, к которым подключаются элементы памяти и элементы, поддерживающие опорное напряжение. Считан может быть сигнал только с одного элемента памяти столбца, ключи остальных элементов столбца в это время закрыты, но открыты все элементы строки, потенциалом, подаваемым на адресную шину строки. При этом заряды всей строки поступают на усилители, все данные записываются в выходной регистр данных и через некоторое время могут быть считаны. Такая операция называется активизацией строки.
Регистр данных или триггер-усилитель, выполняет также функции элемента, который автоматически осуществляет регенерацию информации. Еще раз подчеркнем, что регенерация информации в рассматриваемой схеме производится сразу во всей строке. Считывание информации происходит при установке сигнала чтения на шине управления, по команде записи происходит запись информации. Пока строка остается активной, возможны считывание или запись и других ячеек памяти строки. После того, как истечет время активности строки происходит ее закрытие, которое сопровождается подзарядкой (Precharge) элементов памяти строки. Последующее считывание данных этой строки невозможно без ее повторной активизации (установки адреса строки).
Микросхема динамической памяти. Главные особенности микросхем динамической памяти заключаются в следующем:
· необходимы логические схемы, обеспечивающие регенерацию
информации;
· максимально проста схема накопителя, обеспечивающая минимум занимаемой площади;
· мала потребляемая мощность, поскольку динамический запоминающий элемент не потребляет тока в отрезки времени, когда к нему не происходит обращение.
Для формирования внутренних сигналов, управляющих включением и выключением в определенной последовательности различных узлов микросхемы, в ее структуре предусмотрена схема управления.
Входные, выходные и управляющие сигналы микросхемы памяти: RAS (Row Adress Strobe) - строб адреса строки; CAS (Column Adress Strobe) - строб адреса столбца; WЕ (запись/чтение); вход и выход данных (D0 – Dk).
Микросхема имеет: усилители считывания и
регенерации в каждом столбце матрицы, регистр адреса, дешифраторы адреса строк
и адреса столбцов, устройство управления, устройство ввода и вывода данных.
Структура микросхемы приведена на рис.2.
На линиях RAS (row address strobe - строб адреса строки) и CAS (column address strobe - строб адреса столбца) в спокойном состоянии поддерживается высокий уровень сигнала, что означает, что никакой информации на адресных линиях нет и никаких действий, связанных с чтением или записью данных. В случае регенерации, регенерация осуществляется путем обращения к каждой строке динамической памяти перебором строчных адресов.
В современных микросхемах памяти регенерацию производит устройство регенерации, встроенное в микросхему памяти. Нарушение режима регенерации может привести к нарушению логических состояний микросхем памяти. Поэтому при регенерации применяются защитные схемы, поддерживающие истинность логических состояний элементов матрицы микросхемы памяти, которые работают совместно с генератором циклов регенерации. Микросхема подключается к шине адреса, данных и шине управления. Линии адреса служат для выбора адреса ячейки памяти, а линии данных - для чтения или записи данных в память. Линии управления служат для передачи стробов (импульсов) RAS и CAS и сигнала типа операции WE (Write Enable, разрешение записи) – чтение/запись. CS – выбор кристалла ( crystal selection), используется для объединения микросхем в единую группу в модуле памяти, к которой можно обращаться одновременно.
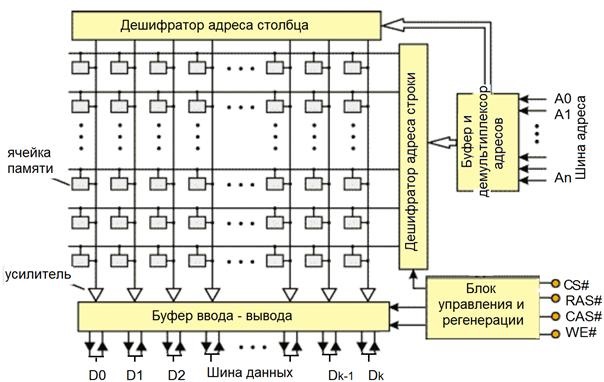
Рис.2 Структура простейшей микросхемы динамической памяти
Обычно, низкий уровень сигнала WЕ готовит микросхему к считыванию состояния шины данных и записи полученной информации в соответствующую ячейку, а высокий, наоборот, заставляет считать содержимое ячейки и установить его на линиях шины данных.
Использование одной и той же шины данных для вывода данных и для чтения данных позволяет в два раза уменьшить количество выводов шины данных. Это, как и уменьшение ширины шины адреса позволяет уменьшить размеры микросхемы, а значит, получить более высокие рабочие частоты.
Рассмотрим, какие факторы мешают повышению рабочей частоты микросхемы памяти:
· скорости распространения электрических сигналов ограничены, поэтому длины проводников, подведенных к различным ножкам микросхемы, не должны сильно отличаться друг от друга, иначе сигнал от одного вывода будет опережать сигнал от другого;
· длины проводников не должны быть очень велики, т.к. задержка распространения сигнала не позволит повысить частоту передачи данных, а значит и быстродействие;
· любой проводник действует как приемная и как передающая антенна, создавая помехи. Уровень помех резко усиливается с ростом тактовой частоты;
· любая линия связи обладает электрической емкостью. Чем больше емкость, тем меньше скорость передачи данных;
· совмещение выводов шины для вывода и ввода данных не позволяет осуществлять чтение и запись одновременно.
Интересно отметить, что в первых компьютерах специальная схема прерывала работу процессора на время регенерации, и процессор сам управлял процессом регенерации.
На рис.3. показана микросхема асинхронной
динамической памяти, в которой разрядность данных - 1 бит.
Микросхемы памяти могут иметь и другую организацию. Например,
распространенные в 2006 г. микросемы (чипы) синхронной динамической памяти DDR
SDRAM фирмы Samsung : K 4 H
5 6 0 8 3 8 E —
T C B 3 (рис.8.5) имеют емкость 36 мегабайт (256
мегабит). Адресуемая ячейка памяти микросхемы 8 битная.
Рис.3. Микросхема памяти DDR SDRAM фирмы Samsung
Микросхему памяти емкостью 512 Мбит можно cоставить, например, из 128М (134 217 728) 4-битных элементов, 64М (67 108 864) 8-битных элементов или 32М (33 554 432) 16-битных элементов –соответствующие конфигурации записываются как "128Mx4", "64Mx8" и "32Mx16". Первая из этих цифр именуется глубиной микросхемы памяти, вторая - шириной (в битах).
Для увеличения емкости микросхемы памяти в настоящее время используется 3D технология создания микросхем. Так компания Nanya Technology изготовила 8-Гбитную DDR3-микросхему в упаковке QDP (quad-die package), четыре кристалла в одном корпусе. При этом для соединения кристаллов используется технология TSV (through silicon via) 3D, через отверстия в кристаллах, что создает систему коротких соединений, позволяющих использовать более высокие частоты при создании модулей памяти, по сравнению с микросхемами 2 D.
SDRAM (Synchronous DRAM) – синхронная динамическая память. Появление вычислительных систем с системными шинами, работающими на частоте 100 MГц и выше привело к пересмотру механизма управления памятью. Была разработана синхронная динамическая память - SDRAM (Synchronous-DRAM).
Микросхемы SDRAM памяти работают синхронно с системной шиной, в них реализован усовершенствованный пакетный режим обмена. Контроллер может запросить одну или несколько последовательных ячеек памяти, или всю строку целиком. Для выполнения такой операции требуется адресный счетчик, не ограниченный двумя битами, как в BEDO-DRAM.
Количество (матриц) банков микросхемы памяти SDRAM увеличено с одного до двух или даже четырех. В настоящее время синхронная память может иметь до 16 банков. Это позволяет обращаться к ячейкам одного банка, осуществляя регенерацию другого, что вдвое увеличивает предельно допустимую тактовую частоту.
Помимо этого появилась возможность одновременного открытия двух (четырех) страниц памяти, причем открытие одной страницы (то есть передача номера строки) может происходить во время считывания информации с другой, что позволяет обращаться по новому адресу столбца ячейки памяти на каждом тактовом цикле.
В отличие от всех видов асинхронной памяти, выполняющих перезапись ячеек памяти при закрытии страницы (то есть при деактивизации сигнала RAS), синхронная память проделывает эту операцию автоматически, позволяя держать страницы открытыми сколь угодно долго.
В режиме саморегенерации (self refresh) микросхемы периодически выполняют циклы регенерации по внутреннему таймеру, в этом режиме они не реагируют на внешние сигналы, и внешняя синхронизация может быть запрещена.
Разрядность шины данных увеличилась с 32 до 64 бит, что еще вдвое увеличило производительность синхронной памяти.
Формула чтения произвольной ячейки из закрытой строки
для SDRAM обычно выглядит так: 5-1-1-1, а из открытой строки так:
3-1-1-1.
Синхронизация операций в памяти тактовыми сигналами
процессорной шины упрощает реализацию интерфейсов и уменьшает время обращения к
столбцу. Режим обмена данными с SDRAM программируется при помощи
внутрикристального регистра режима. При программировании задается длина пакета
и запаздывание, что позволяет произвести оптимальную настройку системы обмена
процессор - память. Упрощенная структура микрхемы памяти SDRAM показана на рис.
4.
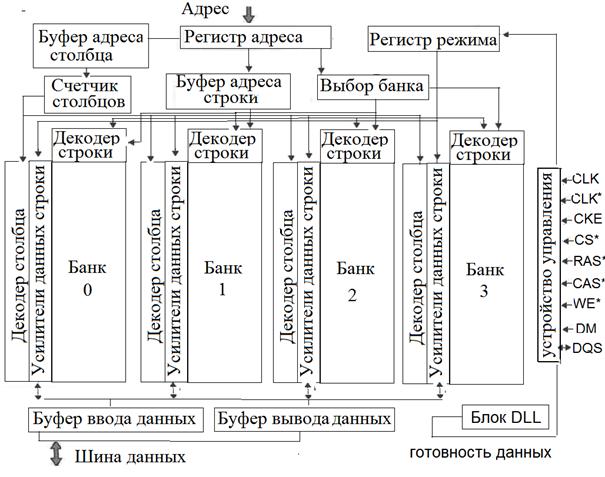
Микросхема памяти имеет дополнительные входы для управления:
- CLK – сигнал синхронизации. Сигнал синхронизации подается в дифференциальной форме по двум линиям, CLK и CLK# (differential clock inputs);
- DQS – сигнал готовности данных. Для синхронизации данных в интерфейс микросхемы памяти введен новый двунаправленный стробирующий сигнал DQS. Строб генерируется источником данных: при операциях чтения DQS генерируется микросхемой памяти, при записи — контроллером памяти;
- CKE (Clock Enable) – сигнал для управления средствами энергосбережения, вход разрешения синхронизации. При подаче на вход СКЕ низкого уровня, микросхема переходит в режим пониженного потребления.
Блок DLL выполняет синхронизацию фронтов DQS и CLK в заданном диапазоне частот синхронизации. Отключение DLL производится при снижении тактовой частоты (в целях энергосбережения).
Корпорация NEC ввела новую технологию памяти - VCM (Virtual Channel Memory), повышающую производительность вычислительных систем приблизительно на 20%. Изменилась внутренняя конструкция модуля памяти. Единственный внутренний канал модуля памяти расщепляется на множество виртуальных, информация образует очередь. Наиболее простой VCM- микросхема представляет собой 64 мегабитную SDRAM, включающую 16 виртуальных каналов памяти.
Синхронная динамическая память SDRAM, в отличие от стандартной и асинхронной DRAM, имеет внутренний таймер ввода данных. Системный таймер, который пошагово контролирует деятельность микропроцессора, управляет и работой SDRAM.
Свойства SDRAM:
· синхронное функционирование;
· чередование банков;
· возможность работы в пакетно-конвейерном режиме. Конвейерная адресация позволяет осуществлять доступ к запрошенным вторыми данными, до завершения обработки запрошенных первыми данными.
Следующий шаг в развитии SDRAМ-DDR
SDRAM DDR SDRAM
(Double Data Rate SDRAM) или SDRAM II.
Эта синхронная память может передавать данные по переднему фронту и спаду сигнала синхронизации шины, что позволило увеличить пропускную способность до 1.6 Гб/сек при частоте шины в 100MHz.
Пропускная способность памяти увеличилась вдвое по сравнению с ранее существовавшей SDRAM. Synchronous DRAM II, или DDR (Double Data Rate - удвоенная скорость передачи данных) основана на тех же самых принципах, что и SDRAM, однако включает некоторые усовершенствования, позволяющие увеличить быстродействие.
Основные
отличия от стандартной SDRAM:
· Используется синхронизация по фронту и по спаду, отсутствующая в SDRAM. DDR фактически увеличивает скорость доступа вдвое, по сравнению с SDRAM, используя при этом ту же частоту, так как позволяет читать данные по восходящему и падающему уровню, выполняя два доступа за время одного обращения стандартной SDRAM;
· DDR использует DLL (delay-locked loop - цикл с фиксированной задержкой) для выдачи сигнала DataStrobe, означающего доступность данных на выходных контактах.
· Используя один сигнал DataStrobe на каждые 16 выводов даных, контроллер памяти может осуществлять доступ к данным более точно и синхронизировать данные, поступающие из разных модулей памяти, находящихся в одном банке;
· Дополнительно, DDR может работать на большей частоте благодаря замене сигналов TTL уровня (порядка 4В) на сигналы более низких уровней SSTL3 (порядка 1,8 B).
Более простым и эффективным для производителей микросхем памяти, исходя из технологических и экономических соображений, является решение – увеличить в 2 раза ширину внутренней шины данных (по сравнению с шириной внешней шины).
Такая архитектура применяется в DDR SDRAM и называется архитектурой «2n-предвыборки» (2n-prefetch). В этой архитектуре доступ к данным осуществляется «попарно» - каждая одиночная команда чтения данных приводит к отправке по внешней шине данных двух элементов (разрядность которых, как и в SDR SDRAM, равна разрядности внешней шины данных). Аналогично, каждая команда записи данных ожидает поступления двух элементов по внешней шине данных.
Временные задержки в работе микросхем памяти
Принято различать несколько разных таймингов памяти, соответствующих задержкам между различными командами. Для того чтобы более подробно разобраться с таймингами памяти, рассмотрим последовательность команд при чтении и записи данных в память.
RAS-to-CAS Delay (tRCD) – время между командами ACTIVE и READ. При подаче сигнала RAS происходит активизация нужной строки памяти (команда ACTIVE), для чего сигнал RAS переводится в низкий уровень и происходит считывание адреса строки и адреса банка. Далее следует команда записи (WRITE) или чтения (READ) данных, для чего сигнал CAS переводится в низкий уровень и в надлежащий уровень устанавливается сигнал WE. При установке CAS в низкий уровень после прихода положительного фронта тактирующего импульса происходит выборка адреса столбца, установленного на шине адреса, и открывается доступ к нужному столбцу матрицы памяти. Однако команда чтения или записи не может следовать непосредственно за командой активизации— требуется, чтобы между этими командами, то есть между импульсами RAS и CAS, существовал некий промежуток времени — RAS-to-CAS Delay (задержка сигнала CAS относительно сигнала RAS). Эту задержку, измеряемую в тактах системной шины, принято обозначать tRCD. Учитывая, что импульс RAS эквивалентен выполнению команды активизации строки (ACTIVE), а импульс CAS — команде READ, под задержкой RAS-to-CAS Delay можно понимать время между командами ACTIVE и READ (рис. 5).
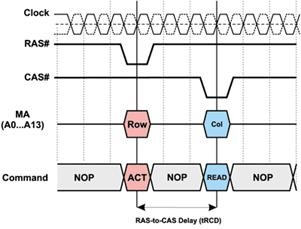
5. Задержка RAS-to-CAS Delay (tRCD)
CAS Latency (tCL). От команды чтения (записи) данных и до выдачи первого
элемента данных на шину (записи данных в ячейку памяти) проходит
промежуток времени, который называется CAS Latency (рис. 6). Эта задержка
измеряется в тактах системной шины и обозначается tCL. Каждый последующий
элемент данных появляется на шине данных в очередном такте.
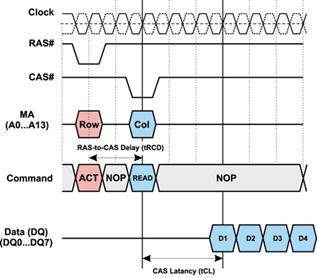
Рис. 6. Задержка CAS Latency (tCL)
Active-to-precharge delay (tRAS). Еще один тип задержки, называемый Active-to-precharge delay, — это минимальный промежуток времени, который должен пройти с момента подачи команды активизации строки до команды PRECHARGE (рис. 7.). Эта задержка обозначается tRAS и измеряется в тактах системной шины.
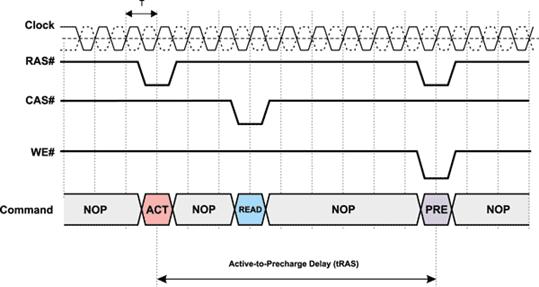
Рис. 7. Задержка Active-to-precharge (tRAS)
RAS Precharge (tRP). Завершение цикла обращения к банку памяти осуществляется подачей команды PRECHARGE, приводящей к закрытию строки памяти. От команды PRECHARGE и до поступления новой команды активизации строки памяти должен пройти промежуток времени (tRP), называемый RAS Precharge (рис. 8).
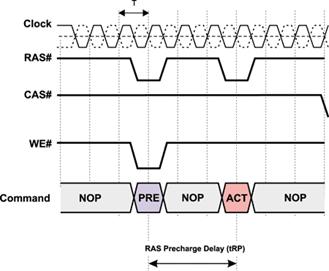
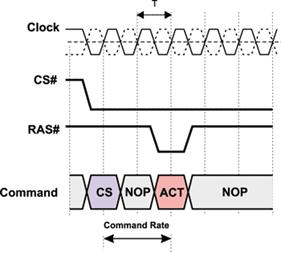
Command Rate. Следующий тип задержки – это скорость выполнения команд (Command Rate), представляющая
собой задержку в тактах системной шины между командой CS# выбора микросхемы и командой активизации строки (рис.
9). Как правило, задержка Command Rate составляет один или два такта (1T или
2T).
Модуль динамической памяти
Память, устанавливаемая в слоты (разъемы) расширения памяти персонального компьютера или других вычислительных систем, изготавливается в виде отдельных модулей.
Модуль - маленькая печатная плата, на которой размещены микросхемы памяти. На рис. 10 показан DIMM модуль памяти емкостью всего 256 МБ, построенный на микросхемах (чипах) K 4 H 5 6 0 8 3 8 E — T C B 3. 8 таких микросхем устанавливается на одном модуле DDR DIMM и дают его полную емкость в 256 МБ.
Абревиатура DIMM (Dual In-Line Memory Module) означает
- модуль памяти с двойным выводом контактов. DIMM модули имеют 64-х
битные шины адреса и данных. Используя DIMM модули можно устанавливать
всего одну плату памяти, так как чередование банков памяти обеспечивается
внутренней структурой микросхем.
8 бит - это разрядность ячейки памяти микросхемы памяти, следовательно восемь установленных на DIMM модуле микросхем обеспечивают в сумме 64 бита шины данных для всего модуля DDR DIMM. В микросхеме имеется четыре внутренних банка памяти, поэтому и модуль памяти имеет 4 банка памяти. Микросхемы (и модуль) требуют 2,5 вольта питания. Время доступа к данным микросхемы K4H560838 E – TCB3 составляет 6 нс. Так как память синхронная, то обращение к данным происходит каждый такт. Она работает на частоте 166 МГц, пропускная способность памяти с учетом DDR определится так: ((2*166) * 64) =21 Гбит/сек. или 2,6 Гбайт/сек.
DIMM с контролем четности ECC требует ширину шины данных 72 бита. Объём модуля равен произведению объёма одной микросхемы на число микросхем. При использовании ECC это число дополнительно умножается на коэффициент 8/9, так как на каждый байт приходится один бит избыточности для контроля ошибок.
Общая разрядность модуля равна произведению разрядности одной микросхемы на число чипов в линейке микросхем, образующих ранг.
Чтобы обеспечить широкую пол ос у выборки данных и большой объем модуля памяти, микр ос хемы связываются в ранги. Ранг памяти имеет общую шину адреса и дополняющие друг друга линии данных. На одном модуле может размещаться несколько рангов. Можно, например, расположить на том же модуле еще один ряд из восьми микросхем, увеличив объем памяти в 2 раза, микросхема будет иметь два ранга. Для выбора ранга потребуется ввести еще одну адресную линию, «0» – выбор 0-го ранга, «1» – выбор первого ранга. Но если нужно больше памяти, то добавлять ранги можно и дальше, установкой нескольких модулей на одной плате и используя тот же принцип: все ранги подключены к одной адресной шине, только сигналы CS разные - у каждого ранга свой.
Существуют модули, выполненные в форм-факторах DIMM (Dual In-line Memory Module) или SO-DIMM (Small Outline Dual In-line Memory Module). Первый предназначается для использования в полноценных настольных компьютерах, а второй — для установки в ноутбуки.
Несмотря на один и тот же форм-фактор, модули памяти разных поколений отличаются количеством контактов. Например, SDRAM имеет 144 контакта для подключения к материнской плате, DDR — 184, DDR2 — 214 контактов, DDR3 — 240, а DDR4 — 288.
Устройства, выполненные в форм-факторе SO-DIMM, имеют меньшее число контактов в силу своих меньших размеров. Например, модуль памяти DDR4 SO-DIMM имеет 256 контактов.
Для синхронной памяти характерен следующий алгоритм работы: после получения запрос а на ту или иную строку информации, размещенной в микросхеме памяти, контроллер памяти подает запрос на активизацию необходимого банка данных (Activate) и дожидается истечения задержки RAS-to-CAS Delay. По ее истечении происходит первый этап чтения, активируемый командой Read, после которого контроллер вновь выжидает CAS Latency Time. В это время информация переписывается в буфер памяти, и уже оттуда, запрошенная в начале транзакции строка данных попадает в контроллер памяти. Описанная последовательность операций чтения может быть проведена еще раз лишь по истечении задержки Row-to-Row Delay. Слабость этого протокола открывается при подаче трех последовательно идущих запросов активизации разных банков, когда первый сигнал чтения "перекрывается" третьим сигналом активизации и должен создать конфликт в управляющих линиях. Чтобы его избежать, контроллер памяти с поддержкой первого поколения DDR "откладывает" выполнение третьего сигнала активации банка памяти, из-за чего пространство канала памяти используется неэффективно, так как при работе нескольких приложений, активно применяющих ресурсы оперативной памяти, в трафике канала наблюдается слишком много "пустых" тактов.
Модули памяти типа DDR2 SDRAM являются логическим продолжением развития
архитектуры «2n-prefetch», применяемой в устройствах DDR SDRAM. Вполне
естественно ожидать, что архитектура устройств DDR2 SDRAM именуется
«4n-prefetch» и подразумевает, что ширина внутренней шины данных оказывается
уже не в два, а в четыре раза больше по сравнению с шириной внешней шины
данных. Расширение внутренней шины данных позволяет снизить внутреннюю частоту
функционирования микр ос хем DDR2 SDRAM в два раза по сравнению с частотой
функционирования микр ос хем DDR SDRAM, обладающих равной теоретической пропускной
сп ос обн ос тью. На рис.11 показан процесс передачи
данных в процессор при использовании 4-х банков.
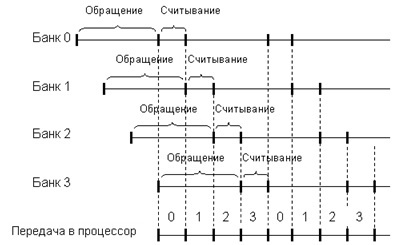
Рис.11. Процесс передачи данных в процессор при использовании 4-х банков памяти
С одной стороны получаем снижение внутренней частоты функционирования микросхем, наряду со снижением номинального питающего напряжения с 2.5 до 1.8 V (вследствие применения нового, по тому времени, 90-нм технологического процесса), что позволяет ощутимо снизить мощность, потребляемую устройствами памяти. С другой стороны, архитектура 4n-prefetch микросхем DDR2 позволяет достичь вдвое большую частоту внешней шины данных по сравнению с частотой внешней шины данных микросхем DDR - при равной внутренней частоте функционирования самих микросхем. Все операции внутри микросхемы памяти осуществляются на уровне «4-х элементных» блоков данных.
В случае памяти DDR на материнской плате устанавливаются терминирующие резисторы, согласующие сопротивление в длинных линиях и не допускающие отражений сигналов (обычно они располагались в ряд параллельно слотам DIMM). Как показано на рис. 12, это приводит к отражениям от неактивной в данный момент микросхемы памяти.
В случае встроенной терминации (используемой в DDR2) поглощение отражения происходит внутри самой микросхемы памяти. Во избежание ослабления сигнала, идущего к активному банку, добавляются переключатели, отключающие встроенную терминацию одновременно с доступом к микросхеме памяти и включающие ее при переходе микросхемы в режим active/standby.
Схема отложенного CAS подразумевает подачу сигналов запросов на активизацию необходимого банка данных и начала чтения в буфер памяти (Read) без задержки CAS Latency Time. Конечно, на практике без задержки обойтись нельзя (активизация банка не может произойти мгновенно), благодаря логике аддитивной латентности достигается увеличение эффективности использования физического пространства канала. Логика аддитивного времени выжидания (встроенная в микросхемы памяти) отслеживает все сигналы активизации банков и автоматически посылает сигналы чтения после их обнаружения. В результате, сразу после задержки CAS, память способна выдавать данные в чипсет, вне зависимости от числа сигналов активизации.
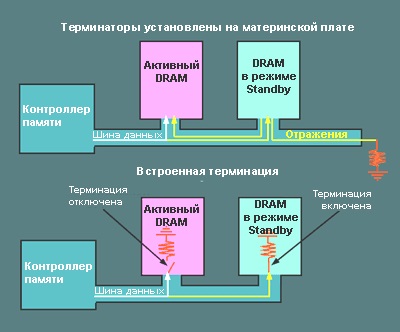
Рис. 12. Действие встроенной терминации
Модули памяти DDR3 SDRAM. Теоретическая пропускная способность микрос хем DDR3 должна быть вдвое выше по сравнению с DDR2 по схеме 8n-prefetch (против 4n-prefetch в DDR2). Количество логических банков в микросхемах DDR3 также увеличено вдвое по сравнению с типичным значением для DDR2 (4 банка) и составляет 8 банков, что теоретически позволяет увеличить «параллелизм» при обращении к данным по схеме чередования логических банков.
Микросхемы DDR3 помещаются в корпус, обладающий рядом улучшений по сравнению с DDR2, а именно:
· большим количеством контактов питания и «земли»,
· усовершенствованным распределением питающих и сигнальных контактов, позволяющим достичь лучшего качества электрического сигнала (необходимое для более устойчивого функционирования на высоких частотах).
В модулях памяти DDR2 подача адресов и команд осуществляется параллельно на все микросхемы модуля, в связи с чем, например, при считывании данных все восемь восьмибитных элемента данных окажутся доступными в один и тот же момент времени и контроллер памяти сможет одновременно прочитать все 64 бита данных.
В модулях памяти DDR3, применяется «пролетная» архитектура подачи адресов и команд. Каждая из микросхем модуля получает команды и адреса с определенным отставанием относительно предыдущей микросхемы. Элементы данных тоже оказываются доступными с некоторым отставанием относительно элементов данных, соответствующих предыдущей микросхеме в ряду, составляющем физический банк модуля памяти (рис.13) .
Контроллер памяти использует определенное смещение по времени при приеме/передаче данных, соответствующее «запаздыванию» поступления адресов и команд (следовательно, и данных) в определенную микросхему модуля. Этим достигается значительное снижение электрической нагрузки на линии передачи данных, что позволяет увеличить частоту.
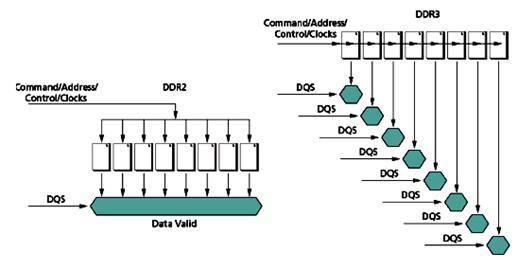
Рис. 13. Отличия в схеме подачи адресов и команд
в памяти DDR2 и DDR3
Поскольку модули памяти DDR3 имеют ту же разрядность, что и модули памяти DDR2 - 64 бита, численные значения рейтингов производительности равно-частотных модулей памяти (6400 байт/с) DDR2 и DDR3 совпадают (например, PC2-6400 для DDR2-800 и PC3-6400 для DDR3-800).
Кроме максимальной пропускной способности, память характеризуется латентностью (задержками). Причем во многих случаях латентность памяти оказывает большее влияние на производительность всей системы в целом, нежели тактовая частота работы памяти.
Под латентностью принято понимать задержку между поступлением команды и ее реализацией. Латентность памяти определяется ее таймингами, то есть задержками, измеряемыми в количествах тактов, между отдельными командами.
Типичные схемы таймингов для модулей памяти DDR3 составляют 9-9-9. Если столь большие относительные значения таймингов, перевести в абсолютные значения (в наносекундах), учитывая все меньшее время цикла (обратно пропорциональное частоте шины памяти), величины задержек становятся вполне приемлемыми. Память типа DDR3-1600 со схемой таймингов 9-9-9 характеризуются величиной задержки всего 11.25 нс, что находится на уровне DDR2-533 с достаточно низкими задержками (схема таймингов 3-3-3).
Одновременно с ростом информационной емкости модулей памяти, при увеличении количества микросхем, растет и емкость электрическая. Постоянная времени зарядки конденсатора прямо пропорциональна емкости. В результате, по мере роста емкости модулей памяти им требуется все больше времени, чтобы принять сигнал от контроллера. Если просто наращивать емкость модуля памяти, то «запаздывание» достигнет такого значения, что нормальная совместная работа двух устройств станет невозможной. Время зарядки конденсатора пропорционально и напряжению, таким образом, снижение напряжения питания микросхем несколько сгладило остроту проблемы. Тем не менее, проблема остается. Было предложено следующее решение - контроллер памяти общается с микросхемами памяти не напрямую, а через микросхему, именуемую буфером, которая сама по себе имеет низкую емкость, и поэтому способна мгновенно принимать сигнал от контроллера, освобождая системную шину. Фактически, буферизованный модуль DIMM содержит встроенный контроллер, играющий роль буфера и снижающего нагрузку на адресную и управляющую шины. Проблема актуальна для серверов – настольные системы с управлением своими объемами памяти справляются. В зависимости от количества банков памяти буферов может быть больше одного. Такая память носит название LR-DIMM (Load Reduced Dual In-Line Memory Module) или и регистровой.
Большинство системных плат разработаны для поддержки небуферизированных модулей памяти, в которых сигналы контроллера памяти передаются без помех или интерференции непосредственно микросхемам памяти. Это наиболее дешевый, эффективный и быстродействующий тип модулей. К его недостаткам относится лишь то, что разработчик системной платы должен определить количество модулей (точнее, число разъемов на системной плате), установка которых допустима, а также ограничить количество микросхем памяти, внедренных на одном модуле.
Для реализации поддержки ос обо большого объема RAM требуются регистровые модули. Быстрые регистровые микр ос хемы временно хранят данные, передаваемые как микр ос хемам памяти, так и от них.
Стандарт DDR4 был реализован в 2012 году, а полномасштабный переход с DDR3 на DDR4 происходит лишь к 2015 году. Intel не делает ставку только на DDR4, новые процессоры продолжают поддерживать память DDR3.
Уровень быстродействия на один разъём в DDR4 равен 1,6 миллиардов пересылок в секунду, с возможн ос тью в будущем д ос тичь максимального уровня 3,2 млрд/с.
Рабочая частота памяти DDR4 с ос тавляет от 2133 МГц до 4266 МГц, что на 1000 МГц больше, чем у DDR3 (1333 МГц и 1666 МГц).
Для памяти с частотой 2133 МГц (наименьшая частота для памяти DDR4) максимальная пропускная сп ос обн ос ть с ос тавляет 2133·8 = 17 064 МБайт/c. Для памяти с частотой 4266 МГц (наибольшая частота, определенная в стандарте) максимальная пропускная сп ос обн ос ть с ос тавляет 4266·8 = 34 128 МБайт/c.
Рабочее
напряжение понижено: 1,1 В - 1,2 В против 1,5 В в
DDR3,
техпроцесс — 32 и 36 нм.
Архитектура DDR4 позволяет осуществлять предварительную выборку 8 бит данных за один такт (8n prefetch) и работу с двумя или четырьмя выбираемыми одновременно группами банков памяти. Это позволяет устройствам проводить независимые друг от друга операции по активизации, чтению, записи и регенерации отдельных банков памяти. Одно из устройств модуля памяти DDR4 показано на рис. 14.
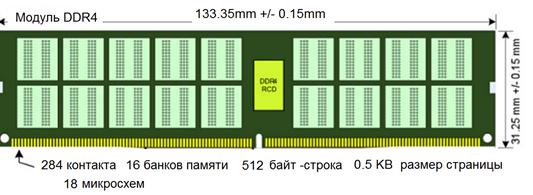
Рис. 14. Устройство
модуля памяти DDR4
Приведенный на рисунке модуль памяти имеет 284 контакта, собран на 18 микросхемах (с контролем четности), имеет 2 ранга (2 линейки микросхем). Включает в себя 16 банков памяти. Ширина одной строки 512 байт (0,5КВ). На рис. 15 показан формат памяти DDR4 для ноутбуков.

Рис. 15. Модули памяти DDR4 для ноутбуков
При построении модуля памяти важно знать, как организованы микросхемы памяти.
В модуле памяти 8Gb x4 DDR4 микр ос хема обычно с ос тоит из 4-х групп банков, по 4 банка в каждой группе. Каждый банк такой микросхемы содержит 217 строк (rows), по 512 байтов каждая.
Для сравнения 8Gb x4 DDR3 микр ос хема содержит 8 независимых банков, 216 строк на банк, по 2048 байтов в каждой строке.
При равном объеме, у DDR4 микр ос хема имеет в два раза больше банков и гораздо короче строки памяти.
Это означает, что новая память может переключаться между банками памяти гораздо быстрее, чем это делала DDR3. В частн ос ти, для 8Gb x4 DDR4 микр ос хем, пропускная сп ос обн ос ть памяти заявлена, как 1600 MT/s (миллионов операций обмена в секунду, megatransfers per second), время активизации банка tFAW(Four-bank Activation Window) равно 20ns, что вдвое меньше, чем у DDR3 (40ns).
DDR4 микросхемы памяти могут открывать произвольные строки в разных банках в два раза быстрее, чем DDR3.
Сравнение DDR3 и DDR4 показывает, что наибольший модуль DDR3, который теоретически может быть сконструирован, может иметь размер 128 GB используя QDP (quad die package – упаковка четырех кристаллов в одну микр ос хему) и 8 Gb микросхемы. Для DDR4, используя 16 Gb микросхемы, и восьмислойную упаковку кристаллов в микросхему, теоретически можно создать модуль памяти объемом до 512GB.
Количество
контактов на модулях DDR4 увеличилось до 284, чтобы адресовать такой объем
памяти. Каждая микросхема модуля памяти DDR4 может представлять собой стек из
2, 4 или 8 кристаллов DRAM. Стек из 8 слоёв описан в дополнениях к спецификации
и, скорее всего, потребует использования технологии TSV (through silicon via)
для своей практической реализации. Межсоединения TSV представляют собой
вертикальные переходные отверстия в кремниевой подложке, заполненные токопроводящим
материалом, которые обеспечивают электрическое соединение между кристаллами
микросхем, расположенными друг над другом (рис.16).
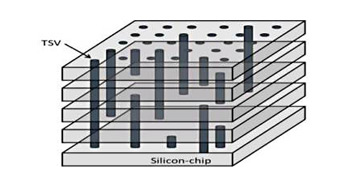
Все перечисленные изменения направлены на создание модулей памяти большей ёмкости и увеличение производительности.
Важным свойством модулей памяти DDR4 является улучшенная энергоэффективность по сравнению с DDR3. Кроме снижения напряжения на I/O с 1.35V до 1.2V, новый стандарт также специфицирует использование более высокого уровня напряжения внутри микросхем (DRAM word line 2.5V), что обеспечивает быстрый доступ в активном режиме и малый ток утечки в пассивном.
Изменилась и электрическая реализация интерфейса ввода-вывода данных.
Новый интерфейс
носит название pseudo-open drain (POD, «псевдо-открытый сток») и
его основное отличие в том, что в схеме не протекает ток, когда на линии
установлен высокий уровень напряжения.
Уменьшение напряжение на I/O, изменения электрического интерфейс а и
уменьшение длины строк в банках памяти приводят к существенному сокращению
энергопотребления по сравнению с DDR3, порядка 30% , однако, это зависит от
характера обращений к памяти, техпроцесса и многих других факторов. Такой
выигрыш может использоваться для того, чтобы увеличить тактовую частоту и,
соответственно, скорость работы, или для того, чтобы сэкономить потребление
энергии при той же производительности.
Возросла надежность памяти DDR4. Введены обнаружение и коррекция микр ос хемами памяти ошибок, связанных с контролем четн ос ти команд и адресов, кроме того микр ос хемы памяти DDR4 имеют режим тестирования соединений. Этот режим позволяет контроллеру памяти проверять электрические связи (и находить «обрыв» линий). Также модуль DDR4 может быть сконфигурирован так, чтобы отбрасывать команды, содержащие ошибки контроля четности. В DDR3 такие команды пропускались и доходили до микросхем памяти, многократно усложняя восстановление после сбоев.
Эти возможности обеспечивают стабильную работу модулей памяти при более высоких рабочих частотах и объемах памяти.
На каждом современном модуле памяти размещается небольшая специализированная микросхема «последовательного обнаружения присутствия» (Serial Presence Detect, SPD). Эта микросхема содержит информацию о типе и конфигурации модуля, временных задержках, которых необходимо придерживаться при выполнении той или иной операции на уровне микросхем памяти, информацию, включающую в себя код производителя модуля, серийный номер, дату изготовления, данные о температурном режиме функционирования модулей. Эти данные могут использоваться, например, для поддержания оптимального температурного режима посредством управления синхронизацией (регулированием скважности импульсов синхросигнала) памяти (троттлинг памяти, DRAM Throttle).
Самыми быстрыми модулями памяти DDR4 (фирма G.Skill) стали модули объёмом 16 ГБ (2х8 ГБ) частотой 4266 МГц. Тайминги памяти, записанные в виде последовательности CL-tRCD-tRP-tRAS составляют 19-23-23-43. В то же время менее производительное решение серии поставляется в модулях по 64 ГБ, при таймингах 14-14-14-34 и работает на частоте 3466 МГц.
Компания Samsung приступила к
массовому производству первых в мире микросхем памяти DRAM DDR4 по техпроцессу
10 нм емк остью 8 Гб, и модулей
памяти, ext-decoration: none; color: windowtext">основанных на
этих чипах. 2 апреля 2019 года Компания
Samsung заявила о завершении разработки 3-го поколения оперативной памяти DDR4
DRAM 10-нанометрового класса, для чего ей не потребовалась экстремальная
ультрафиолетовая литография.
Новая память обеспечит лучшие скорости передачи данных и повышенную энергоэффективность, по сравнению с предыдущей памятью 20 нм класса. Так, прирост скорости передачи данных возрастет на 30% и модули памяти смогут поддерживать передачу данных на скорости до 3200 Мб/с.
Взаимодействие оперативной памяти и процессора
Скорость обмена с памятью определяет быстродействие всей системы. Поэтому в настоящее время контролеры памяти не выпускаются в виде отдельных микросхем, а встраиваются непосредственно в процессор, чтобы повысить быстродействие системы процессор – память.
Пока суммарный объем оперативной памяти, которая используется операционной системой и запущенными приложениями, меньше установленной, процесссор работает, в основном, с оперативной памятью. Если оперативной памяти недостаточно, то система обращается к жесткому диску каждый раз, когда не находит необходимых данных в оперативной памяти. При этом наблюдается резкое снижение скорости работы вычислительной системы.
Минимальная порция информации, которой процессор обменивается с памятью за одно обращение – пакет. Пакет со тоит из двоичных элементов, разрядность каждого элемента соответствует разрядности одной микросхемы памяти.
Пакет необязательно должен храниться в одном массиве. Он разбивается на несколько частей и записывается в разные банки памяти, процессор же считает эти данные единым целым. Чем больше банков имеет память, тем более быстрый обмен данными можно организовать.
За один такт передаётся по одному элементу из выбранного банка каждой микросхемы. То есть, для передачи блока данных, состоящего из шестнадцати элементов, потребуется =1 такт. Если элемент 8-ми разрядный, за такт будет передаваться 128 бит, если 4-х разрядный – 64 бита.
После осуществления любой операции со строкой памяти требуется определенное время для осуществления ее «подзарядки». Преимущество «многобанковых» микросхем SDRAM заключается в том, что можно обращаться к строке одного банка, пока строка другого банка находится на «подзарядке». Можно расположить данные в памяти и организовать к ним доступ таким образом, что далее будут запрашиваться данные из второго банка, уже «подзаряженного» и готового к работе. В этот момент вполне естественно «подзаряжать» первый банк. Это схема доступа к памяти с чередованием банков (Bank Interleave).
В определенный момент времени можно работать только с одной строкой выбранного банка, однако существует возможность работы сразу с несколькими банками, если они объединяются в группы.
Контроллер памяти считывает сразу целый пакет данных (Burst) с каждого бита шины данных микросхемы памяти. Поэтому и передача данных становится пакетной.
Пакетная передача данных (Burst Mode) предназначена для быстрых операций со строками КЭШ памяти процессора. Независимо от размера читаемой ячейки (байт, слово, двойное слово) длина запроса всегда равна размеру строки КЭШ памяти. Один пакетный цикл не может пересекать границу строки КЭШ памяти. Если строка КЭШ памяти процессора имеет длину 64 байта, для ее пересылки потребуется восемь 64-разрядных шинных цикла. Кроме того, имеется специфический порядок следования адресов в пакетном цикле, который определяется начальным адресом пакета (задается процессором) и разрядностью передачи (задается модулем памяти).
Учитывая все оптимизации обработки данных, можно прийти к ситуации, когда память будет работать практически в режиме непрерывной передачи данных из усилителей уровней в буфер обмена.
Буферизация в микросхемах памяти нового типа.
Понятие ранга
Рангом модуля памяти называется количество наборов
микросхем разрядностью 64 бита, подключенных к линии выбора микросхемы (chip
select).
Двухранговый модуль – это два логических модуля, распаянных на печатной плате и
пользующихся поочерёдно одним и тем же физическим каналом передачи данных.
Четырёхранговый – то же самое, что и двухранговый, но уже в четырёхкратном
масштабе (см. рис 17).

Как нетрудно догадаться, организация модуля памяти с
использованием рангов позволяет увеличить объём оперативной памяти, доступной
по единственному набору линий.
Организация модулей памяти с использованием рангов применяется в серверах и
тяжелых рабочих станциях, для достижения максимального объёма оперативной
памяти при ограниченном количестве слотов.
Типы модулей памяти
В настоящее время существует три типа модулей памяти:
· Регистровые (registered);
· Небуферизованные (unbuffered);
· Со сниженной нагрузкой (load reduced).
Регистровые модули памяти
Регистровые модули памяти являются самым
распространёнными и наиболее часто используемыми модулями памяти. Сокращённое
название регистровых модулей, принятое в различных справочниках и спецификациях
– RDIMM.
Наименование «регистровый» означает, что модули этого типа имеют буферизирующий
регистр который используется для буферизации адресных
и командных сигналов (рис. 18):
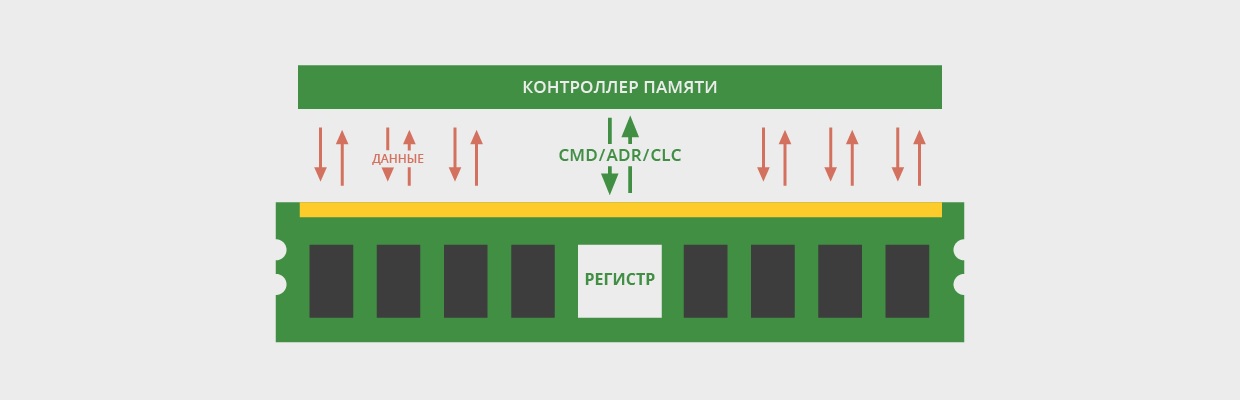
Наличие буферизирующего
регистра позволяет снизить электрическую нагрузку на адресную шину, что, в свою
очередь, позволяет установить в канал больше модулей памяти, но не более восьми
рангов для одного канала.
Недостатком такого решения является незначительное повышение энергопотребления
и увеличение задержек.
Используются модули памяти RDMM в больших, высокопроизводительных серверах, где
требуется большое количество оперативной памяти.
Отдельно хотелось бы отметить, что полностью буферизованные модули памяти
(FBDIMM), в которых буферизация осуществляется для адресных сигналов, сигналов
управления и данных не являются частью стандарта DDR3.
Архитектура FBDIMM поддерживает больше модулей памяти на каждый канал памяти,
но сами по себе модули FBDIMM более дорогие, потребляют больше энергии и
обладают значительной задержкой. Увеличение количества каналов в серверах
последних поколений, использующих процессоры Intel Xeon 5500 и более новые,
сделало невыгодным использование модулей FBDIMM в качестве оперативной памяти.
Небуферизованные модули памяти
Небуферизованные модули памяти
являются вторыми по распространённости и используемости модулями памяти после
регистровых модулей. Сокращённое название небуферизованных модулей – UDIMM.
Наименование «небуферизованный» означает, что в модулях такого типа отсутствуют
какие-либо промежуточные элементы между чипами памяти и контроллером памяти, то
есть чипы памяти посредством адресных и управляющих линий подключаются напрямую
к контроллеру памяти.
Организация подключения модулей памяти без каких-либо промежуточных элементов
обеспечивает наиболее быстрый обмен данными между контроллером и чипами памяти
на модуле, но при этом установка каждого дополнительного модуля в канал
увеличивает электрическую нагрузку на шину. Как следствие, в один канал
контроллера можно установить не боле двух двухранговых модуля UDIMM.
Из-за ограничения на количество устанавливаемых модулей сфера применения
модулей UDIMM ограничена использованием в небольших недорогих серверах.
Несомненным преимуществом модулей UDIMM, также вытекающим из отсутствия
буферизирующих компонентов, является высокая скорость работы и малые задержки.
Модули памяти со сниженной нагрузкой
Модули памяти со сниженной
нагрузкой появились недавно и являются, пожалуй, наиболее редко используемыми
модулями на данный момент. Сокращённое название модулей со сниженной нагрузкой
– LRDIMM, (англ. Load-Reduced DIMM) –
память со сниженной нагрузкой. Это еще один тип ОЗУ с механизмом буферизации.
Модули памяти LRDIMM схожи с модулями RDIMM наличием промежуточного элемента
между контроллером и микросхемами памяти, однако принцип их работы отличается
от принципа работы регистровых модулей DIMM.
Модули LRDIMM оснащаются буфером, который, в отличие от модулей RDIMM,
буферизует не только сигналы управления, но и данные (рис. 19):
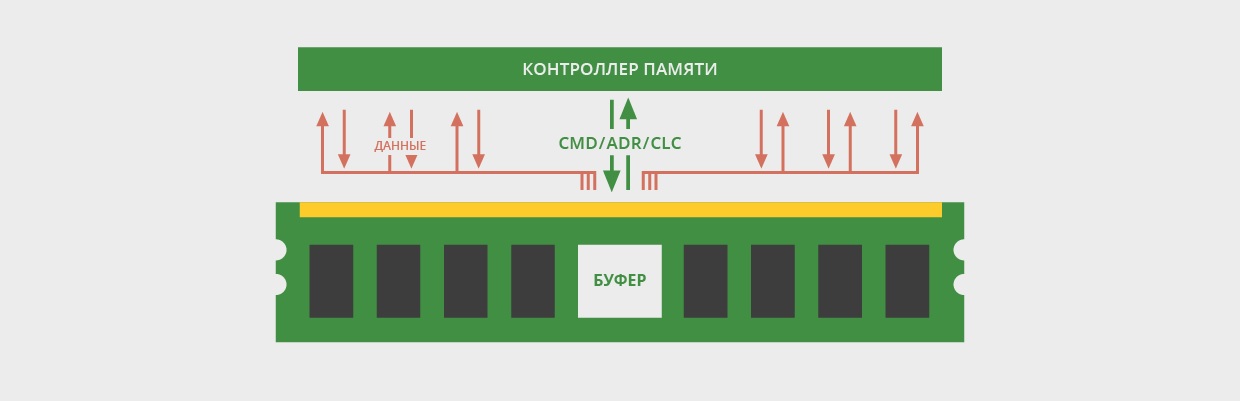
При использовании модулей
RDIMM пользователи сильнее ограничены в возможных вариантах конфигураций
каналов, чем при использовании модулей LRDIMM. При использовании модулей RDIMM
оптимальной является установка не более двух модулей DIMM на канал, поскольку
при использовании третьего банка скорость работы памяти снижается.
Модули LRDIMM не имеют ограничений, присущих модулям RDIMM, потому обладают
механизмом, называемым “умножение рангов” – “ rank multiplication”. Благодаря
этому механизму, четырехранговые модули LRDIMM преобразуются для контроллера
памяти в двухранговые. Благодаря уменьшению электрических рангов модуля LRDIMM
сервер может поддерживать модули LRDIMM с повышенными скоростями по сравнению с
модулями RDIMM.
На рисунке 20 показана организация модулей памяти DDR3 и DDR4.
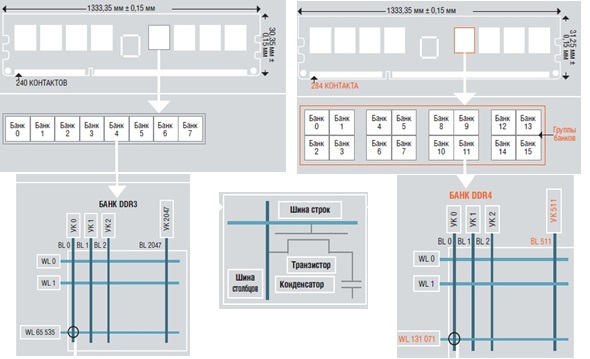
Рис. 20. Организация
модулей памяти DDR3 и DDR4.
Так как модули памяти имеют разную структуру, изменяется и структура контроллера памяти.
Микросхема памяти DDR4 8 Гбит x4 разделяется на 16 банков, а аналогичная по параметрам микросхема DDR3 — на 8 банков. За счет такого разделения длина строки банка уменьшилась в четыре раза (обращение к ячейкам памяти происходит путем указания их адреса в двухмерном массиве — строки и столбца). У памяти DDR3 65536 строк и 2048 столбцов, у памяти DDR4 131072 строки и 511 столбцов. В результате показатель tFAW (time Four Bank Activation Window), характеризующий время, необходимое для открытия произвольной строки в разных банках памяти, у DDR4 уменьшился вдвое – с 40 до 20 нс.
Шина строк микросхемы памяти DDR4 стала короче на три четверти. Банк DDR4 хранит в два раза меньше данных, чем банк DDR3, зато в микросхеме DDR4 банков вдвое больше. Они объединены в группы по четыре. Такое структурирование делает возможной быструю передачу данных из банка через буфер предварительной выборки (специальная архитектура Prefetch) на шину данных. С появлением каждого нового поколения RAM эта передача все более и более усложняется. Для предвыборки данных из группы банков в памяти DDR4 был разработан новый буфер, что позволило производителям значительно повысить тактовую частоту и сохранить ширину внешней шины неизменной.
Низкое энергопотребление – следствие использования коротких шин, для активизации которых не требуется большого количества заряда. Это дает возможность снизить напряжение питания с 1,5 В (DDR3) до 1,2 В (DDR4). К тому же электропитание микросхемы памяти управляемое и при необходимости микросхема может поднять напряжение до 2,5 В.
Микросхема DDR4 умеет динамически регулировать частоту обновления (регенерации данных). В зависимости от рабочей температуры ячейка должна перезаписываться с определенным интервалом – не реже одного раза в 64 мс. У DDR3 эти интервалы постоянны, а микросхема DDR4 перезаписывает данные в зависимости от температуры, сокращая частоту своих обновлений для экономии энергии. Одна только эта особенность помогает DDR4 сэкономить около 20% энергии по сравнению с DDR3.
Схема предварительной выборки данных в микросхемах памяти DDR также совершенствовалась по мере развития архитектуры памяти.
На рис. 21 показано, как изменялась подготовка данных для передачи на внешнюю шину данных с развитием технологии, начиная от синхронной динамической памяти SDRAM до DDR3.
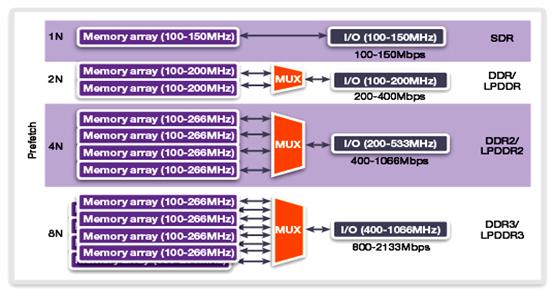
Рис.21. Подготовка данных для передачи в процессор в
микросхемах SDR, DDR, DDR2, DDR3.
Контроллер DDR по сравнению с SDR работает с серией из двух передач, поэтому частота внешней шины может быть увеличена в 2 раза. Контроллер памяти DDR2 работает с серией из 4-х передач, контроллер DDR3 работает с серией из восьми передач, а для модулей DDR4 система передачи данных значительно изменяется.
В микросхемах памяти DDR4 SDRAM осуществляется разделение во времени передачи данных из внутренних банковских групп для того, чтобы скрыть тот факт, что внутри микросхемы SDRAM время основного цикла чтения занимает больше времени за счет увеличения объема памяти.
На
рис. 22 показано, как процесс передачи данных выглядит для четырех
банковских групп в микросхемах памяти DDR4 SDRAM.
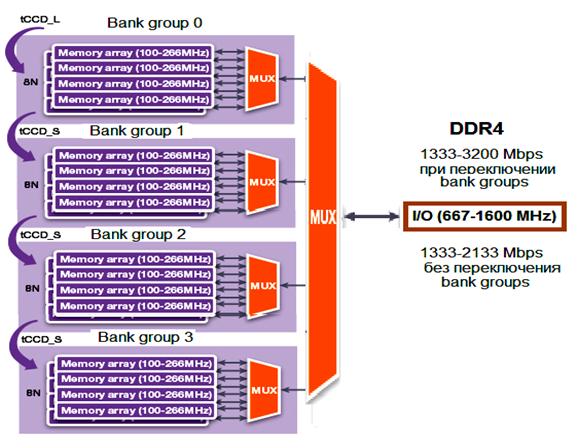
Длина пакета равна четырем, четыре такта занимает передача данных из одного банка. Такая схема дает выигрыш при работе с разными группами банков. Если ведется работа с одной группой банков, то схема работает с той же пропускной способностью, что и DDR3. В зависимости от режима работы изменяется время переключения банков памяти. При работе с одной группой банков это время больше (tCCD_L на рисунке). При переключении на другую группу банков время меньше (tCCD_S на рисунке).
При использовании разных групп исключены потери пропускной способности шины и одна команда может следовать за другой без пропущенных циклов на шине данных.
Как
показано на рисунке 23, время задержки обращения к банку при использовании
различных банковских групп для DDR4 составляет четыре такта.
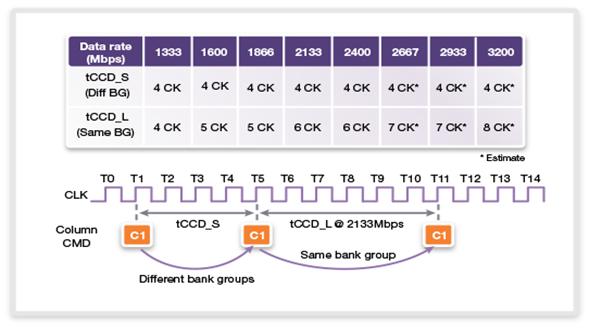
Рис. 23. Задержки при использовании различных
банковских групп микросхемы DDR4 и одной банковской группы, в зависимости
от частоты.
Оставаясь
в той же банковской группе для скорости передачи 2133 Мбит/с, требуется уже
шесть тактов для активизации следующей колонки.
Для передачи данных по шине данных требуется 4 такта. Два такта, или 33% от
пропускной способности шины потеряны.
Задержки, связанные с работой памяти на уровне физических банков относятся к особой категории таймингов, не связанных с д ос тупом к данным, находящимся в ячейках микр ос хем SDRAM. Эти задержки считаются «задержками командного интерфейса», а обратная им характеристика – «скоростью подачи команд» (command rate).
При инициализации подсистемы памяти каждому сигналу выбора кристалла (chip select), ассоциированному с определенным физическим банком памяти, в регистрах микросхемы памяти присваивается определенный номер, уникальным образом идентифицирующий данный физический банк при каждом последующем запросе. Все физические банки разделяют одни и те же шины команд, адресов и данных. Чем больше физических банков памяти присутствует на общей шине, тем больше электрическая емкостная нагрузка на нее, с одной стороны, и тем больше задержка распространения сигнала (как прямое следствие протяженности пути сигнала) плюс задержка кодирования/декодирования и работы логики адресации и управления. Так возникают задержки на уровне командного интерфейс а. В настройках подсистемы памяти в BIOS может присутствовать настройка параметра «Command Rate: 1T/2T». Выбор 2Т замедлит работу памяти и такую установку рекомендовано использовать только, если память работает нестабильно.
Дальнейшее развитие памяти – DDR5 SDRAM.
Основное внимание при разработке DDR5 SDRAM было уделено вопросам повышения производительности памяти, которая попрежнему не поспевает за растущими потребностями многоядерных процессоров. Поэтому ожидается, что первые модули новой памяти со старта возьмут рубеж в 4,8 Гбит/с на контакт, то есть DDR5-4800. А впоследствии скорости будут прогрессировать до 6,4 Гбит/с. При этом стоит иметь в виду, что производители памяти для настольных систем часто выходят за рамки спецификаций, поэтому не стоит удивляться, если рано или поздно на рынке появятся, в том числе и модули DDR5-8400 или им подобные.
В основе роста скоростей лежит не рост
тактовой частоты ядер памяти, которая масштабируются с большим трудом. Вместо
этого разработчики традиционно занимаются увеличением параллелизма. Ключевой
идеей, внедрённой в стандарте DDR5, выступает разделение одного модуля на два
независимых канала. Иными словами, в то время как в DDR4 данные передаются по
шине шириной 64 бит, в DDR5 используется две независимые шины по 32 бит (или 40
бит с ECC). Попутно длина пакета (Burst Length) для каждого канала увеличена с
8 до 16, что выливается в пересылку по 64 байт за такт по каждому каналу одного
модуля. Это значит, что при одинаковой частоте ядра технология DDR5 предлагает
удвоение пропускной способности по сравнению с DDR4.

Рис. 24. Модуль памяти DDR5
Отдельно стоит подчеркнуть, что реализованная в DDR5 передача данных порциями по 64 байт позволяет синхронизировать работу оперативной памяти с функционированием типичной процессорной кеш-памяти, где также используются строки по 64 байт.
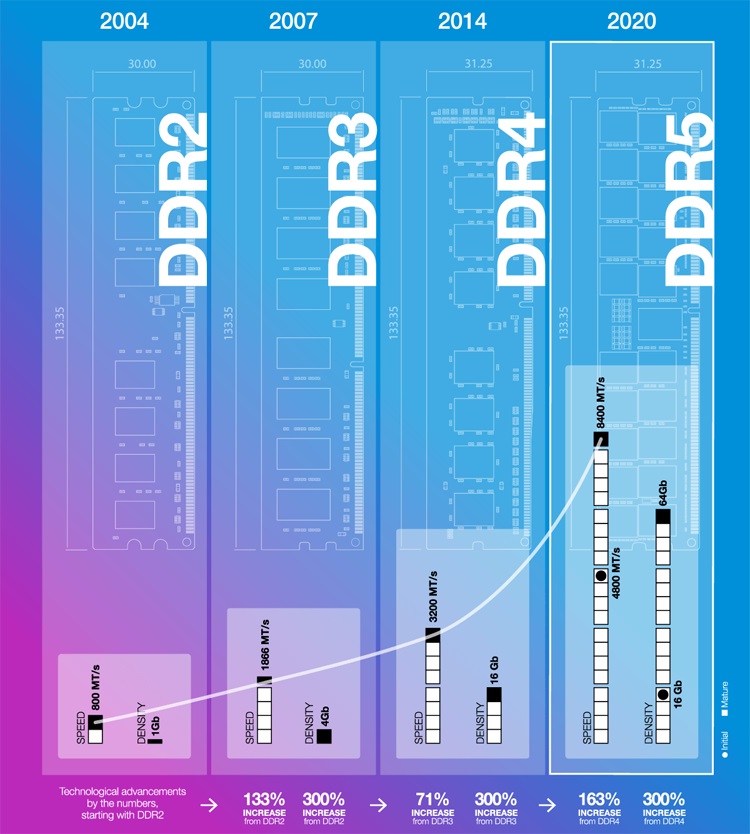
Рис. 25. Рост производительности памяти с 2004 года по 2020 год
Вместе с другими изменениями, такими как раздельное обновление содержимого банков вместе с увеличением числа групп банков, всё это позволяет достичь дополнительного прироста реальной производительности благодаря снижению накладных расходов. Результаты моделирования показывают, что даже при сравнении модулей памяти DDR4 и DDR5 с формально одинаковой скоростью (например, 3,2 Гбит/с), новая память обеспечивает в 1,36 раза более высокую эффективную пропускную способность. При сравнении же DDR5-4800 и DDR4-3200 оценочная производительность первой оказывается выше в 1,87 раз.
Ещё одним важным шагом вперёд стало увеличение предельной ёмкости одного чипа до 64 Гбит, что в 4 раза превышает ёмкость чипов DDR4. Таким образом, при штабелировании по 8 чипов в микросхеме и использовании 32 чипов в модуле (это возможно в случае LRDIMM) ёмкость одного модуля может быть доведена до внушительных 2 Тбайт. Впрочем, если говорить о небуферизованных DIMM для потребительских систем, то стандарт DDR5 делает возможным создание модулей объёмом по 128 Гбайт, что тоже совсем неплохо.
Спецификация DDR5 предполагает, что новые модули памяти будут требовать напряжения 1,1 В и улучшат свою энергоэффективность. При этом DIMM нового стандарта продолжат использовать 288-контактный форм-фактор. Впрочем, другое назначение выводов и изменённое расположение ключей в слоте не позволит по ошибке установить DDR5 DIMM в слоты для DDR4 SDRAM.
Стоит понимать, что сегодня речь идёт только о появлении стандарта, в то время как широкого распространения DDR5 SDRAM придётся подождать ещё как минимум год или полтора. AMD планирует внедрить работу с DDR5 лишь в архитектуре Zen 4, которая выйдет в 2022 году. Intel же начнёт поддерживать DDR5 SDRAM с серверных процессоров Sapphire Rapids, которые, вероятно, выйдут в следующем году.
Чтобы увеличить объем памяти в разъемы памяти устанавливается несколько модулей. При этом большое количество рангов электрически нагружает шину и контроллер памяти замедляет работу модуля памяти. Поэтому стали применять многоканальную архитектуру, которая позволяет независимо обращаться к нескольким модулям.
На рис.26. Показана организация одноканального режима работы памяти. Каждый модуль имеет свой базовый адрес.
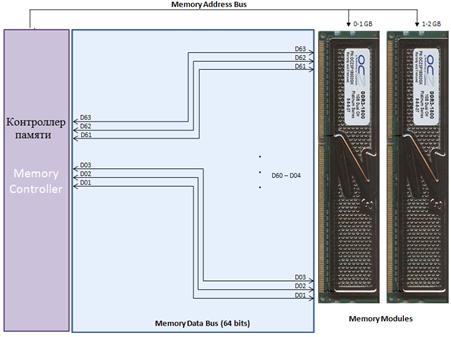
Рис. 26. Одноканальный режим работы памяти
Увеличивать количество модулей при такой организации памяти очень сложная задача, поскольку одновременно нужно не ухудшать и скоростные характеристики. Поэтому на смену одноканальной архитектуры памяти пришла многоканальная архитектура. Организация двухканального режима памяти показана на рисунке 27.
Оба модуля имеют один адрес. Данные читаются параллельно сразу из двух модулей.
Для DDR3 конструкция шины Multi-Drop предусматривает использование всего лишь двух каналов для связи модулей с контроллером памяти. При использовании четырех модулей DIMM каждые два модуля соединяются с контроллером посредством одного канала, что негативно сказывается на производительности подсистемы памяти.
Двух-, трех-, и четырехканальная архитектуры работают за счет увеличения числа проводников в шине данных памяти, соответственно удваивая, утраивая или учетверяя пропускную способность памяти.
Многоканальный режим обязательно должен поддерживаться контроллером памяти. При этом память DDR4 использует топологию «точка-точка».
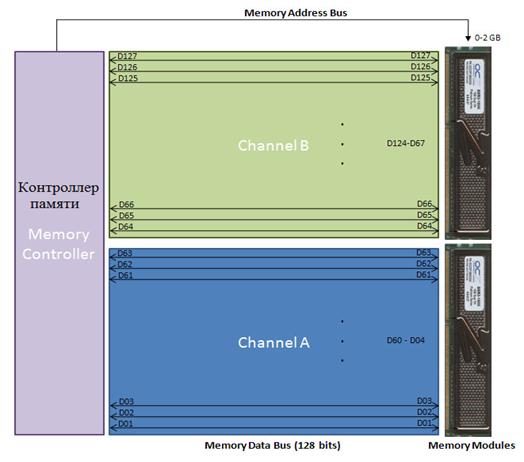
Для каждого DIMM – модуля предусмотрен отдельный канал, то есть каждый модуль памяти будет напрямую связываться с контроллером и не делить ни с кем этот канал. У такого подхода есть и свои недостатки. Например, двухканальные системы будут ограничены двумя разъемами DIMM, четырехканальные — четырьмя.
Соотношения между таймингами памяти
Естественно, для каждого типа памяти значения различных задержек не могут быть произвольными и выбираются из допустимых значений. Кроме того, между таймингами должны соблюдаться вполне определенные соотношения.
Процессоры
серии Intel Haswell-E и материнские
платы с логикой Intel X99, воспринимающие только память DDR4, выпущены в 2014
году, к этому времени компания G.Skill подготовила партию
комплектов ОЗУ стандарта DDR4.
На
рис.28. показан модуль памяти G.Skill Ripjaws 4 F4-3000C15Q-16GRR. Рабочая
частота памяти DDR4-3000, рекомендуемые тайминги –(15-15-15-35), рабочее
напряжение – 1,35 В, количество и объём каждого модуля
(4 модуля по 4 ГБ), дата производства (ноябрь 2014 года).

Рис.28. Модуль памяти G.Skill Ripjaws 4 F4-3000C15Q-16GRR.
На
рис. 29 показаны микросхемы памяти, установленные в модуле. Компоновка модулей
односторонняя, то есть все восемь микросхем памяти распаяны на одной стороне
печатной платы.

Рис. 29. Микросхемы памяти, установленные на
плате модуля
Емкость каждой микросхемы 512 МБ.
Организация модуля – 512 х 8.
Включает 16 банков по 32 МБ каждый.
Частота работы памяти 1067 MHz, длительность такта 0,938ns.
Память не буферизованная ( не регистровая).
На рис. 30 приведены XMP параметры модуля. XMP (Extreme Memory Profile) профиль - это набор данных о расширенных и нестандартных возможностях определённого модуля оперативной памяти (частотах, таймингах, напряжениях).
На начальном этапе загрузки компьютера BIOS материнской платы считывает эту информацию из микр ос хемы SPD оперативной памяти и оперативная память работает на оптимизированных частотах и таймингах, находящихся в профиле XMP, конечно для этого нужна поддержка технологии XMP материнской платой.
Практически все современные материнские платы способны задействовать профиль XMP с помощью настроек БИ ОС (по умолчанию он не задействован). Если профиль XMP не задействован, значит, материнская плата выставляет стандартные частоту, тайминги и напряжение, в соответствии со своими заводскими характеристиками.
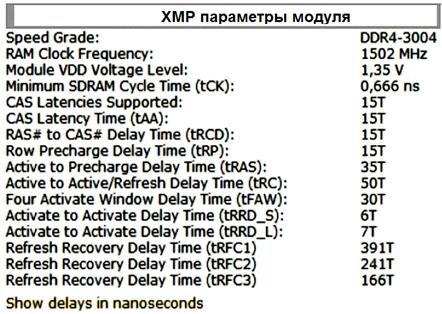
Рис. 30. XMP параметры модуля
Временной промежуток между активизацией строки и командой чтения определяется временем tRCD, а временной промежуток между командой чтения и появлением данных на шине – tCL (CAS Latency).
tRCD, этот параметр в современных микросхемах памяти связан с t-RAS через длину пакета данных, которая установлена в данной системе. Пакет — это минимальная порция информации, которой процессор обменивается с памятью «за один раз».
Временной промежуток между началом считывания данных и закрытием активной строки (tRAS) зависит от длины передаваемого пакета, при этом должно выполняться соотношение tRAS > tRCD+tCL.
Минимальное значение tRAS должно быть больше суммы tRCD и tCL на столько, на сколько велика длительн ос ть третьей операции, определяемая длиной передаваемого пакета.
В данном случае величины задержек tCL = 15 тактам, и tRCD = 15 тактов, поэтому (tRAS > 34). При длине пакета = 4 необходимо затратить не менее 4 тактов для передачи пакета, поэтому значение tRAS должно быть больше 34 тактов.
Описанные задержки — RAS-to-CAS Delay (tRCD), CAS Latency (tCL), RAS Precharge (tRP), Active-to-precharge delay (tRAS) и Command Rate — определяют тайминги памяти, обычно записываемые в виде последовательности CL-tRCD-tRP-tRAS-Command Rate. К примеру, для модуля DDR4 тайминги можно записать: 15-15-15-35-(2T).
Временные параметры задержек работы памяти G.Skill Ripjaws 4 F4-3000C15Q-16GRR показаны на рис. 31.
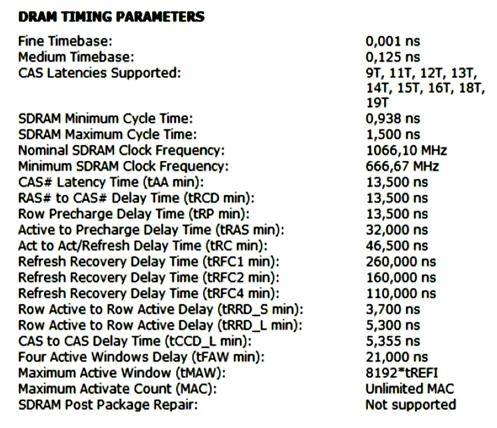
Рис. 31. Временные параметры модуля памяти
Параметр tRFC определяе минимальное время между двумя циклами регенерации, либо между началом цикла регенерации и следующем чтением строки в буферный усилитель, зависит от расположения модуля памяти.
Стоит обратить внимание на то, что если тактовые частоты системной шины и памяти не могут быть соотнесены как целые числа, возникают штрафные задержки, негативно сказывающиеся на производительности системы процессор – память.
Другой немаловажный момент - политика открытия страниц и максимально возможное количество одновременно открываемых страниц. Удерживание сигнала RAS в микросхеме памяти позволяет читать ячейки в пределах открытой страницы передачей одного лишь адреса столбца, что значительно увеличивает производительность системы. Чем больше страниц удерживается в открытом состоянии, тем выше вероятность того, что очередной запрос попадет в уже открытую страницу и потому обработается значительно быстрее.
На
рис. 32. приведены особенности архитектурной организации памяти G.Skill
Ripjaws 4 F4-3000C15Q-16GRR.

Рис. 32. Особенности архитектурной организации памяти
Отсюда следует, что модуль памяти типа UDIMM – небуферизован, память имеет 1 ранг, для адресации 4-х групп банков выделено 2 бита, и 4 бита используется для адресации каждого из 8 банков в группе, разрядность каждой микросхемы модуля 8 бит, разрядность шины 64 бита.
Параметры 4-х канальной DDR4 памяти, определенные программой CPU-Z, показаны на рис. 33.
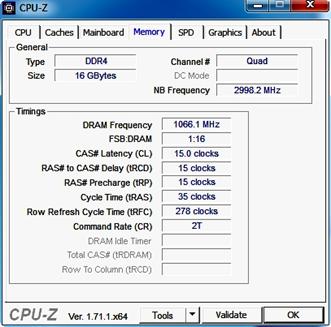
Рис. 33. Параметры 4-х канальной памяти DDR4
Параметр NB Frequency – показывает частоту контроллера оперативной памяти. Это частота работы контроллера памяти с КЭШ процессора (2998,2 МГц). С оперативной памятью контроллер работает на частоте 1066,1 МГц.
Работа контроллера памяти
Вычисление
полного времени доступа к памяти.
Рассмотрим несколько соотношений между таймингами на примере типичных операций чтения данных.
В простейшем случае для чтения данных из памяти необходимо выполнить последовательность следующих операций:
· активизировать строку в банке памяти ( команда ACTIVE);
· подать команду чтения данных (команда READ);
· считать данные, поступающие на внешнюю шину данных;
· закрыть активизированную строку (команда PRECHARGE);
· активизировать строку в банке памяти (команда ACTIVE).
Вспомним формулы для определения времени доступа к памяти и определим их значения по приведенным выше данным в худшем случае время обращения к ячейке памяти (Tобр) составляет:
Tобр= (RAS to CAS Delay + CAS Delay + RAS
precharge) =
(15+15+15) 0,938 = 42, 21нс.
В лучшем случае, если строка активна:
Tобр= CAS Delay = 14,07нс.
Если память
готова к обращению и не требует регенерации:
Tобр= ( RAS to CAS Delay + CAS Delay) =
28,14нс.
Процесс обращения к памяти по шагам.
Последовательность работы системы процессор - память будет следующей:
· Процессор (вернее кэш-контроллер третьего уровня) запрашивает 64 или 128 байтов памяти и передает запрос контроллеру памяти. Контроллер памяти вычисляет номер столбца и строки первой ячейки цепочки и смотрит открыта соответствующая строка или нет. Если строка действительно открыта, то контроллер памяти выставляет сигнал CAS и спустя 15 тактов (в зависимости от величины задержки CAS, обусловленной качеством микросхемы памяти) на шине появляются данные;
· контроллер памяти считывает за один такт одно слово пакета, еще один такт на каждое слово расходуется на передачу данных процессору;
· если требуемая строка закрыта, но максимально допустимое количество одновременно открытых строк еще не достигнуто, контроллер поылает микросхеме памяти сигнал RAS вместе с адресом строки, затем посылает сигнал CAS и все происходит по сценарию, описанному выше;
· в том случае, когда требуемая строка закрыта и открыто максимально допустимое количество других строк, требуется дополнительное время на закрытие строки.
Частота ядра процессора в нашем случае примерно в 3 раза превышает частоту шины памяти, тогда чтение ячейки памяти занимает от тридцати до девяноста тактов системной шины процессора!
Таким образом, приходим к выводу, что производительность подсистемы “процессор” - память все еще оставляет желать лучшего. Причем, современная ситуация даже хуже, чем она была в конце восьмидесятых годов прошлого века, когда использовались процессоры с тактовой частотой порядка 10 МГц (длительность такта 100нс), а время доступа к оперативной памяти составляло 200 нс, то есть, всего 2 такта системной шины, хотя большинство арифметических команд выполнялось за десятки тактов. Современные процессоры тратят на чтение произвольной ячейки памяти иногда около сотни тактов, выполняя в это же самое время более четырех вычислительных инструкций за такт, вот почему процессору просто необходима для согласования скоростей работы системы “процессор - оперативная память” быстрая буферная КЭШ - память.
Настройка памяти
Контроллер памяти в процессоре находится на уровне внеядерной логики (Uncore Logic). Элементы уровня Uncore Logic не синхронизованы по частоте с элементами уровня Core Logic (ядрами процессора). Поэтому для настройки памяти в разделе Memory Optimization системы BIOS необходимо установить значение коэффициента UCLK Multiplier, то есть коэффициента умножения для элементов уровня Uncore Logic.
Для процессора Intel Core i7-965 Extreme Edition по умолчанию значение коэффициента UCLK Multiplier с ос тавляет 20. Это означает, что для элементов уровня Uncore Logic базовой является частота 2,66 ГГц (133,33 МГц x 20 = = 2,66 ГГц). Однако из этого не следует, что все элементы уровня Uncore Logic (контроллер памяти, контроллер QPI, кэш L3) функционируют на данной частоте, поскольку для элементов Uncore Logic могут использоваться и внутренние коэффициенты умножения. Кроме того, нужно учитывать, что внутренняя частота работы контроллера и внешняя частота, которую контроллер «выдает» на шину (к примеру, частота работы памяти), — это не одно и то же. Частота работы памяти задается коэффициентом Memory Multiplier. При этом опорной частотой для памяти является частота в 133,33 МГц. Следовательно, если мы хотим задать частоту DDR3-памяти 1333 МГц, то коэффициенту Memory Multiplier необходимо присвоить значение 10. При значении 12 частота памяти станет равной 1600 МГц, значение 8 соответствует частоте 1066 МГц, а 6 — частоте 800 МГц.
Кроме задания частоты памяти, можно настраивать тайминги памяти и задавать напряжение питания. Настройке подлежат следующие тайминги:
· ·tCL (CAS Latency) — промежуток времени между поступлением команды чтения (записи) данных (сигнал CAS# переводится в низкий уровень) до выдачи первого элемента данных на шину (записи данных в ячейку памяти);
· tRCD (RAS to CAS Delay) — промежуток времени между командой активизации нужной строки памяти (команда ACTIVE) (сигнал RAS# переводится в низкий уровень и происходит считывание адреса логического банка памяти и строки в этом банке памяти) до команды записи (WRITE) или чтения (READ) данных (сигнал CAS# переводится в низкий уровень);
· tRP (RAS Precharge Time) — минимальный промежуток времени между командой активизации и командой записи (WRITE) или чтения (READ) данных уже другой строки памяти (в следующем логическом банке);
· tRASmin (RAS Precharge Time) — минимальный промежуток времени, который должен пройти с момента подачи команды активизации строки (RAS#) до команды PRECHARGE (завершение цикла обращения к банку памяти ос уществляется подачей команды PRECHARGE, приводящей к закрытию строки памяти). Фактически tRASmin — это время, в течение которого строка остается активизированной;
· tRFC (RAS Refresh Cycle Timing) — минимальный промежуток времени между активизацией двух различных строк одного и того же логического банка памяти;
· tRRD (RAS to RAS Delay) — минимальный промежуток времени между командами активизации строк (RAS#) в разных логических банках памяти;
· tWR (Write Recovery Time) — минимальный промежуток времени между приемом последней порции данных, подлежащих записи, и готовностью строки памяти к ее закрытию с помощью команды PRECHARGE;
· tWTR (Write to Read Delay) — минимальный промежуток времени между приемом последней порции данных, подлежащих записи, и командой чтения;
· tRPT (Read to Precharge Time) — минимальный промежуток времени между подачей команды на чтение до команды Precharge;
· Command Rate — задержка в тактах системной шины между командой CS# выбора чипа и командой активации строки. Задержка Command Rate составляет один или два такта (1T или 2T).